Commit be6b Fixed full path to external files was not being displayed correctly in SHOW CREATE TABLE
Issue #1052 rt_attr_json column won’t work with columnar storage
[gl #3287] Crash on possibly out of space disk
[gl 548] Fixed DocidIndex cost calculation
[gl 3361] Fixed index hints to support multiple attributes
[gl #3363] Updated export ranker output to match packedfactors()
Commit 2196 fixed wildcards at query to not be affected by ignore_chars
Commit 1990 fixed crash of daemon at federated query with aggregate
Commit 6fbc fixed json range filter to work with int64 values
Commit 3e4d fixed percolate query to handle exact term modifier
Commit 7d08 fixed wrong behavior when exceptions fold multiple lines at the stopwords
Commit 4f4b fixed wrong charset mapping for duplicates
Commit 0bf1 fixed string functions upper and lower to work with multibyte string
Commit 0297 fixed daemon crash on processing search with pseudo-sharding enabled and UDF with JSON argument
Commit 8505 fixed exact symbol can be escaped; fixed double exact expansion by expand_keyword option
Commit e9bc fixed HTTP error on processing bulk requests; fixed return error to client from net loop
Commit c86d fixed SphinxQL packet larger 16Mb to properly return to client
Commit e90f fixed daemon crash on query with packedfactors and large internal buffer
Commit 6e1b fixed daemon crash on invalid manticore.json config
Commit 9916 fixed replication to not bind to localhost for host name with multiple IP
Commit 18a0 fixed select list expression with alias could hides index attribute; fixed sum to count in int64 for integer
Commit 2a00 added date_format select list expression that exposes strftime function
Commit ec19 fixed suggest for short words; added sentence option to show whole qsuggest sentence
Commit 1d3f fixed duplicate documents at the result set for the query with not_terms_only_allowed option to RT index with killed documents
Commit 122b fixed error of alter with empty string for external files; fixed RT index external files left after alter of external files
Major new features
Query optimizer now works for fulltext queries
Minor changes
Fixed DocidIndex cost calculation
Added warnings on invalid index hints
Queries using count(*) with a single filter now utilize precalculated data from secondary indexes (if available), resulting in significantly faster query times.
String fields/attributes that are both indexed and attribute are now treated as a single field on INSERT, DESC and ALTER.
Field and attribute order is now consistent between SHOW CREATE TABLE and DESC.
When executing INSERT queries and running out of disk space to write binlog entries, new INSERT queries will fail until there’s enough free disk space available.
Issue #1062 The /bulk endpoint reports information regarding the number of processed and non-processed strings (documents) in case of an error.
The /bulk endpoint processes empty lines as a commit command.
Behaviour changes
⚠️ BREAKING CHANGE Document IDs are now treated as unsigned 64-bit integers on indexing and INSERT.
⚠️ BREAKING CHANGE Query optimizer hints now have a new syntax (e.g. /+ SecondaryIndex(uid) /). Old syntax is no longer supported.
Next maintenance release
Bugfixes
Commit a062 fixed crash on replication of update with JSON and string attribute
[gl #3363] Updated export ranker output to match packedfactors()
Version 6.0.4
Released: March 15 2023
New features
Improved integration with Logstash, Beats etc. including:
Support for Logstash versions >= 7.13.
Auto-schema support.
Added handling of bulk requests in Elasticsearch-like format.
Buddy commit fba9 Display original error on invalid request received.
Buddy commit db95 Allow spaces in backup path and add some magic to regexp to support single quotes also.
Version 6.0.2
Released: Feb 10 2023
Bugfixes
Issue #1024 crash 2 Crash / Segmentation Fault on Facet search with larger number of results
❗Issue #1029 - WARNING: Compiled-in value KNOWN_CREATE_SIZE (16) is less than measured (208). Consider to fix the value!
❗Issue #1032 - Manticore 6.0.0 plain index crashes
❗Issue #1033 - multiple distributed lost on daemon restart
❗Issue #1064 - race condition in tokenizer lowercase tables
Version 6.0.0
Released: Feb 7 2023
Starting with this release, Manticore Search comes with Manticore Buddy, a sidecar daemon written in PHP that handles high-level functionality that does not require super low latency or high throughput. Manticore Buddy operates behind the scenes, and you may not even realize it is running. Although it is invisible to the end user, it was a significant challenge to make Manticore Buddy easily installable and compatible with the main C++-based daemon. This major change will allow the team to develop a wide range of new high-level features, such as shards orchestration, access control and authentication, and various integrations like mysqldump, DBeaver, Grafana mysql connector. For now it already handles SHOW QUERIES, BACKUP and Auto schema.
This release also includes more than 130 bug fixes and numerous features, many of which can be considered major.
Major Changes
🔬 Experimental: you can now execute Elasticsearch-compatible insert and replace JSON queries which enables using Manticore with tools like Logstash (version < 7.13), Filebeat and other tools from the Beats family. Enabled by default. You can disable it using SET GLOBAL ES_COMPAT=off.
Commit c436 Auto-schema: you can now skip creating a table, just insert the first document and Manticore will create the table automatically based on its fields. Read more about this in detail here. You can turn it on/off using searchd.auto_schema.
Vast revamp of cost-based optimizer which lowers query response time in many cases.
Issue #1008 Parallelization performance estimate in CBO.
Commit cef9 Encoding stats of columnar tables/fields are now stored in the meta data to help CBO make smarter decisions.
Commit 2b95 Added CBO hints for fine-tuning its behaviour.
Telemetry: we are excited to announce the addition of telemetry in this release. This feature allows us to collect anonymous and depersonalized metrics that will help us improve the performance and user experience of our product. Rest assured, all data collected is completely anonymous and will not be linked to any personal information. This feature can be easily turned off in the settings if desired.
Commit c470 New settings accurate_aggregation and max_matches_increase_threshold for controlled aggregation accuracy.
Issue #718 Support for signed negative 64-bit IDs. Note, you still can’t use IDs > 2^63, but you can now use ids in the range of from -2^63 to 0.
As we recently added support for secondary indexes, things became confusing as “index” could refer to a secondary index, a full-text index, or a plain/real-time index. To reduce confusion, we are renaming the latter to “table”. The following SQL/command line commands are affected by this change. Their old versions are deprecated, but still functional:
index <table name> => table <table name>,
searchd -i / --index => searchd -t / --table,
SHOW INDEX STATUS => SHOW TABLE STATUS,
SHOW INDEX SETTINGS => SHOW TABLE SETTINGS,
FLUSH RTINDEX => FLUSH TABLE,
OPTIMIZE INDEX => OPTIMIZE TABLE,
ATTACH TABLE plain TO RTINDEX rt => ATTACH TABLE plain TO TABLE rt,
RELOAD INDEX => RELOAD TABLE,
RELOAD INDEXES => RELOAD TABLES.
We are not planning to make the old forms obsolete, but to ensure compatibility with the documentation, we recommend changing the names in your application. What will be changed in a future release is the “index” to “table” rename in the output of various SQL and JSON commands.
Queries with stateful UDFs are now forced to be executed in a single thread.
Issue #1011 Refactoring of all related to time scheduling as a prerequisite for parallel chunks merging.
⚠️ BREAKING CHANGE: Columnar storage format has been changed. You need to rebuild those tables that have columnar attributes.
⚠️ BREAKING CHANGE: Secondary indexes file format has been changed, so if you are using secondary indexes for searching and have searchd.secondary_indexes = 1 in your configuration file, be aware that the new Manticore version will skip loading the tables that have secondary indexes. It’s recommended to:
Before you upgrade change searchd.secondary_indexes to 0 in the configuration file.
Run the instance. Manticore will load up the tables with a warning.
Run ALTER TABLE <table name> REBUILD SECONDARY for each index to rebuild secondary indexes.
If you are running a replication cluster, you’ll need to run ALTER TABLE <table name> REBUILD SECONDARY on all the nodes or follow this instruction with just change: run the ALTER .. REBUILD SECONDARY instead of the OPTIMIZE.
⚠️ BREAKING CHANGE: The binlog version has been updated, so any binlogs from previous versions will not be replayed. It is important to ensure that Manticore Search is stopped cleanly during the upgrade process. This means that there should be no binlog files in /var/lib/manticore/binlog/ except for binlog.meta after stopping the previous instance.
Issue #849SHOW SETTINGS: you can now see the settings from the configuration file from inside Manticore.
Issue #1013 Previously a table record could be removed by Manticore from the index list if it couldn’t start serving it on start. The new behaviour is to keep it in the list to try to load it on the next start.
indextool –docextract returns all the words and hits belonging to requested document.
Commit 2b29 Environment variable dump_corrupt_meta enables dumping a corrupted table meta data to log in case searchd can’t load the index.
Commit c7a3DEBUG META can show max_matches and pseudo sharding statistics.
Commit 6bca A better error instead of the confusing “Index header format is not json, will try it as binary…”.
Commit bef3 Ukirainian lemmatizer path has been changed.
It’s now possible to install a specific version using APT.
Commit a6b8 Windows installer (previously we provided just an archive).
Switched to compiling using CLang 15.
⚠️ BREAKING CHANGE: Custom Homebrew formulas including the formula for Manticore Columnar Library. To install Manticore, MCL and any other necessary components, use the following command brew install manticoresoftware/manticore/manticoresearch manticoresoftware/manticore/manticore-extra.
Issue #947 In some cases a single simple select could cause the whole instance stall, so you couldn’t log in to it or run any other query until the running select is done.
Commit 4092 Discard uncommitted txns if index altered (or it can crash)
Commit 9692 Query syntax error when using backslash
Commit 0c19 workers_clients could be wrong in SHOW STATUS
Commit 1772 fixed a crash on merging ram segments w/o docstores
Commit f45b Fixed missed ALL/ANY condition for equals JSON filter
Commit 3e83 Replication could fail with got exception while reading ist stream: mkstemp(./gmb_pF6TJi) failed: 13 (Permission denied) if the searchd was started from a directory it can’t write to.
Commit 92e5 Since 4.0.2 crash log included only offsets. This commit fixes that.
Version 5.0.2
Released: May 30th 2022
Bugfixes
❗Issue #791 - wrong stack size could cause a crash.
Version 5.0.0
Released: May 18th 2022
Major new features
🔬 Support for Manticore Columnar Library 1.15.2, which enables Secondary indexes beta version. Building secondary indexes is on by default for plain and real-time columnar and row-wise indexes (if Manticore Columnar Library is in use), but to enable it for searching you need to set secondary_indexes = 1 either in your configuration file or using SET GLOBAL. The new functionality is supported in all operating systems except old Debian Stretch and Ubuntu Xenial.
Read-only mode: you can now specify listeners that process only read queries discarding any writes.
New /cli endpoint for running SQL queries over HTTP even easier.
Faster bulk INSERT/REPLACE/DELETE via JSON over HTTP: previously you could provide multiple write commands via HTTP JSON protocol, but they were processed one by one, now they are handled as a single transaction.
#720Nested filters support in JSON protocol. Previously you couldn’t code things like a=1 and (b=2 or c=3) in JSON: must (AND), should (OR) and must_not (NOT) worked only on the highest level. Now they can be nested.
Support for Chunked transfer encoding in the HTTP protocol. You can now use chunked transfer in your application to transmit large batches with reduced resource consumption (since calculating Content-Length is unnecessary). On the server side, Manticore now always processes incoming HTTP data in a streaming manner, without waiting for the entire batch to be transferred as before, which:
reduces peak RAM usage, lowering the risk of OOM
decreases response time (our tests indicated an 11% reduction for processing a 100MB batch)
allows you to bypass max_packet_size and transfer batches much larger than the maximum allowed value of max_packet_size (128MB), for example, 1GB at a time.
#719 HTTP interface support of 100 Continue: now you can transfer large batches from curl (including curl libraries used by various programming languages) which by default does Expect: 100-continue and waits some time before actually sending the batch. Previously you had to add Expect: header, now it’s not needed.
Previously (note the response time):
$ time curl -v -sX POST http://localhost:9318/bulk -H "Content-Type: application/x-ndjson" --data '{"insert": {"index": "user", "doc": {"name":"Prof. Matt Heaney IV","email":"ibergnaum@yahoo.com","description":"Tempora ullam eaque consequatur. Vero aut minima ut et ut omnis officiis vel. Molestiae quis voluptatum sint numquam.","age":15,"active":1}}}{"insert": {"index": "user", "doc": {"name":"Prof. Boyd McKenzie","email":"carlotta11@hotmail.com","description":"Blanditiis maiores odio corporis eaque illum. Aut et rerum iste. Neque et ullam quisquam officia dignissimos quo cumque.","age":84,"active":1}}}{"insert": {"index": "user", "doc": {"name":"Mr. Johann Smith","email":"stiedemann.tristin@ziemann.com","description":"Temporibus amet magnam consequatur omnis consequatur illo fugit. Debitis natus doloremque est tempore deserunt vero. Harum eos corrupti nemo ut.","age":89,"active":1}}}{"insert": {"index": "user", "doc": {"name":"Hector Pouros","email":"hickle.mafalda@hotmail.com","description":" as voluptatem inventore sit. Aliquam fugit perferendis est id aut odio et sapiente.","age":64,"active":1}}}'* Trying 127.0.0.1...* Connected to localhost (127.0.0.1) port 9318 (#0)>POST /bulk HTTP/1.1>Host: localhost:9318>User-Agent: curl/7.47.0>Accept: */*>Content-Type: application/x-ndjson>Content-Length: 1025>Expect: 100-continue>* Done waiting for 100-continue* We are completely uploaded and fine<HTTP/1.1 200 OK<Server: 4.2.0 15e927b@211223 release (columnar 1.11.4 327b3d4@211223)<Content-Type: application/json;charset=UTF-8<Content-Length: 434<* Connection #0 to host localhost left intact{"items":[{"insert":{"_index":"user","_id":2811798918248005633,"created":true,"result":"created","status":201}},{"insert":{"_index":"user","_id":2811798918248005634,"created":true,"result":"created","status":201}},{"insert":{"_index":"user","_id":2811798918248005635,"created":true,"result":"created","status":201}},{"insert":{"_index":"user","_id":2811798918248005636,"created":true,"result":"created","status":201}}],"errors":false}real 0m1.022suser 0m0.001ssys 0m0.010s
Now:
$ time curl -v -sX POST http://localhost:9318/bulk -H "Content-Type: application/x-ndjson" --data '{"insert": {"index": "user", "doc": {"name":"Prof. Matt Heaney IV","email":"ibergnaum@yahoo.com","description":"Tempora ullam eaque consequatur. Vero aut minima ut et ut omnis officiis vel. Molestiae quis voluptatum sint numquam.","age":15,"active":1}}}{"insert": {"index": "user", "doc": {"name":"Prof. Boyd McKenzie","email":"carlotta11@hotmail.com","description":"Blanditiis maiores odio corporis eaque illum. Aut et rerum iste. Neque et ullam quisquam officia dignissimos quo cumque.","age":84,"active":1}}}{"insert": {"index": "user", "doc": {"name":"Mr. Johann Smith","email":"stiedemann.tristin@ziemann.com","description":"Temporibus amet magnam consequatur omnis consequatur illo fugit. Debitis natus doloremque est tempore deserunt vero. Harum eos corrupti nemo ut.","age":89,"active":1}}}{"insert": {"index": "user", "doc": {"name":"Hector Pouros","email":"hickle.mafalda@hotmail.com","description":" as voluptatem inventore sit. Aliquam fugit perferendis est id aut odio et sapiente.","age":64,"active":1}}}'* Trying 127.0.0.1...* Connected to localhost (127.0.0.1) port 9318 (#0)>POST /bulk HTTP/1.1>Host: localhost:9318>User-Agent: curl/7.47.0>Accept: */*>Content-Type: application/x-ndjson>Content-Length: 1025>Expect: 100-continue><HTTP/1.1 100 Continue<Server: 4.2.1 63e5749@220405 dev<Content-Type: application/json;charset=UTF-8<Content-Length: 0* We are completely uploaded and fine<HTTP/1.1 200 OK<Server: 4.2.1 63e5749@220405 dev<Content-Type: application/json;charset=UTF-8<Content-Length: 147<* Connection #0 to host localhost left intact{"items":[{"bulk":{"_index":"user","_id":2811798919590182916,"created":4,"deleted":0,"updated":0,"result":"created","status":201}}],"errors":false}real 0m0.015suser 0m0.005ssys 0m0.004s
⚠️ BREAKING CHANGE: Pseudo sharding is enabled by default. If you want to disable it make sure you add pseudo_sharding = 0 to section searchd of your Manticore configuration file.
Having at least one full-text field in a real-time/plain index is not mandatory anymore. You can now use Manticore even in cases not having anything to do with full-text search.
Fast fetching for attributes backed by Manticore Columnar Library: queries like select * from <columnar table> are now much faster than previously, especially if there are many fields in the schema.
⚠️ BREAKING CHANGE: Implicit cutoff. Manticore now doesn’t spend time and resources processing data you don’t need in the result set which will be returned. The downside is that it affects total_found in SHOW META and hits.total in JSON output. It is now only accurate in case you see total_relation: eq while total_relation: gte means the actual number of matching documents is greater than the total_found value you’ve got. To retain the previous behaviour you can use search option cutoff=0, which makes total_relation always eq.
⚠️ BREAKING CHANGE: All full-text fields are now stored by default. You need to use stored_fields = (empty value) to make all fields non-stored (i.e. revert to the previous behaviour).
⚠️ BREAKING CHANGE: Index meta file format change. Previously meta files (.meta, .sph) were in binary format, now it’s just json. The new Manticore version will convert older indexes automatically, but:
you can get warning like WARNING: ... syntax error, unexpected TOK_IDENT
you won’t be able to run the index with previous Manticore versions, make sure you have a backup
⚠️ BREAKING CHANGE: Session state support with help of HTTP keep-alive. This makes HTTP stateful when the client supports it too. For example, using the new /cli endpoint and HTTP keep-alive (which is on by default in all browsers) you can call SHOW META after SELECT and it will work the same way it works via mysql. Note, previously Connection: keep-alive HTTP header was supported too, but it only caused reusing the same connection. Since this version it also makes the session stateful.
You can now specify columnar_attrs = * to define all your attributes as columnar in the plain mode which is useful in case the list is long.
Faster replication SST
⚠️ BREAKING CHANGE: Replication protocol has been changed. If you are running a replication cluster, then when upgrading to Manticore 5 you need to:
stop all your nodes first cleanly
and then start the node which was stopped last with --new-cluster (run tool manticore_new_cluster in Linux).
Noise resistance which can help in case of unstable network between replication nodes
Improved logging
Security improvement: Manticore now listens on 127.0.0.1 instead of 0.0.0.0 in case no listen at all is specified in config. Even though in the default configuration which is shipped with Manticore Search the listen setting is specified and it’s not typical to have a configuration with no listen at all, it’s still possible. Previously Manticore would listen on 0.0.0.0 which is not secure, now it listens on 127.0.0.1 which is usually not exposed to the Internet.
Faster aggregation over columnar attributes.
Increased AVG() accuracy: previously Manticore used float internally for aggregations, now it uses double which increases the accuracy significantly.
optimize_cutoff is now available as a per-table setting which can be set when you CREATE or ALTER a table.
⚠️ BREAKING CHANGE: query_log_format is now sphinxql by default. If you are used to plain format you need to add query_log_format = plain to your configuration file.
Significant memory consumption improvements: Manticore consumes significantly less RAM now in case of long and intensive insert/replace/optimize workload in case stored fields are used.
shutdown_timeout default value was increased from 3 seconds to 60 seconds.
Commit ffd0 Support for Java mysql connector >= 6.0.3: in Java mysql connection 6.0.3 they changed the way they connect to mysql which broke compatibility with Manticore. The new behaviour is now supported.
Commit 1da6 disabled saving a new disk chunk on loading an index (e.g. on searchd startup).
Issue #784 count ‘VIP’ connections separately from usual (non-VIP). Previously VIP connections were counted towards the max_connections limit, which could cause “maxed out” error for non-VIP connections. Now VIP connections are not counted towards the limit. Current number of VIP connections can be also seen in SHOW STATUS and status.
Issue #687 support zstd compression for mysql proto
⚠️ Other minor breaking changes
⚠️ BM25F formula has been slightly updated to improve search relevance. This only affects search results in case you use function BM25F(), it doesn’t change behaviour of the default ranking formula.
⚠️ Changed behaviour of REST /sql endpoint: /sql?mode=raw now requires escaping and returns an array.
⚠️ Format change of the response of /bulk INSERT/REPLACE/DELETE requests:
previously each sub-query constituted a separate transaction and resulted in a separate response
now the whole batch is considered a single transaction, which returns a single response
⚠️ Search options low_priority and boolean_simplify now require a value (0/1): previously you could do SELECT ... OPTION low_priority, boolean_simplify, now you need to do SELECT ... OPTION low_priority=1, boolean_simplify=1.
⚠️ If you are using old php, python or java clients please follow the corresponding link and find an updated version. The old versions are not fully compatible with Manticore 5.
⚠️ HTTP JSON requests are now logged in different format in mode query_log_format=sphinxql. Previously only full-text part was logged, now it’s logged as is.
New packages
⚠️ BREAKING CHANGE: because of the new structure when you upgrade to Manticore 5 it’s recommended to remove old packages before you install the new ones:
RPM-based: yum remove manticore*
Debian and Ubuntu: apt remove manticore*
New deb/rpm packages structure. Previous versions provided:
manticore-server with searchd (main search daemon) and all needed for it
manticore-tools with indexer and indextool
manticore including everything
manticore-all RPM as a meta package referring to manticore-server and manticore-tools
The new structure is:
manticore - deb/rpm meta package which installs all the above as dependencies
manticore-server-core - searchd and everything to run it alone
manticore-server - systemd files and other supplementary scripts
manticore-tools - indexer, indextool and other tools
manticore-common - default configuration file, default data directory, default stopwords
manticore-icudata, manticore-dev, manticore-converter didn’t change much
Issue #773 Can’t add column bit(N) to columnar table
Issue #774 “cluster” gets empty on start in manticore.json
❗Commit 1da4 HTTP actions are not tracked in SHOW STATUS
Commit 3810 disable pseudo_sharding for low frequency single keyword queries
Commit 8003 fixed stored attributes vs index merge
Commit cddf generalized distinct value fetchers; added specialized distinct fetchers for columnar strings
Commit fba4 fixed fetching null integer attributes from docstore
Commit f300ranker could be specified twice in query log
Version 4.2.0, Dec 23 2021
Major new features
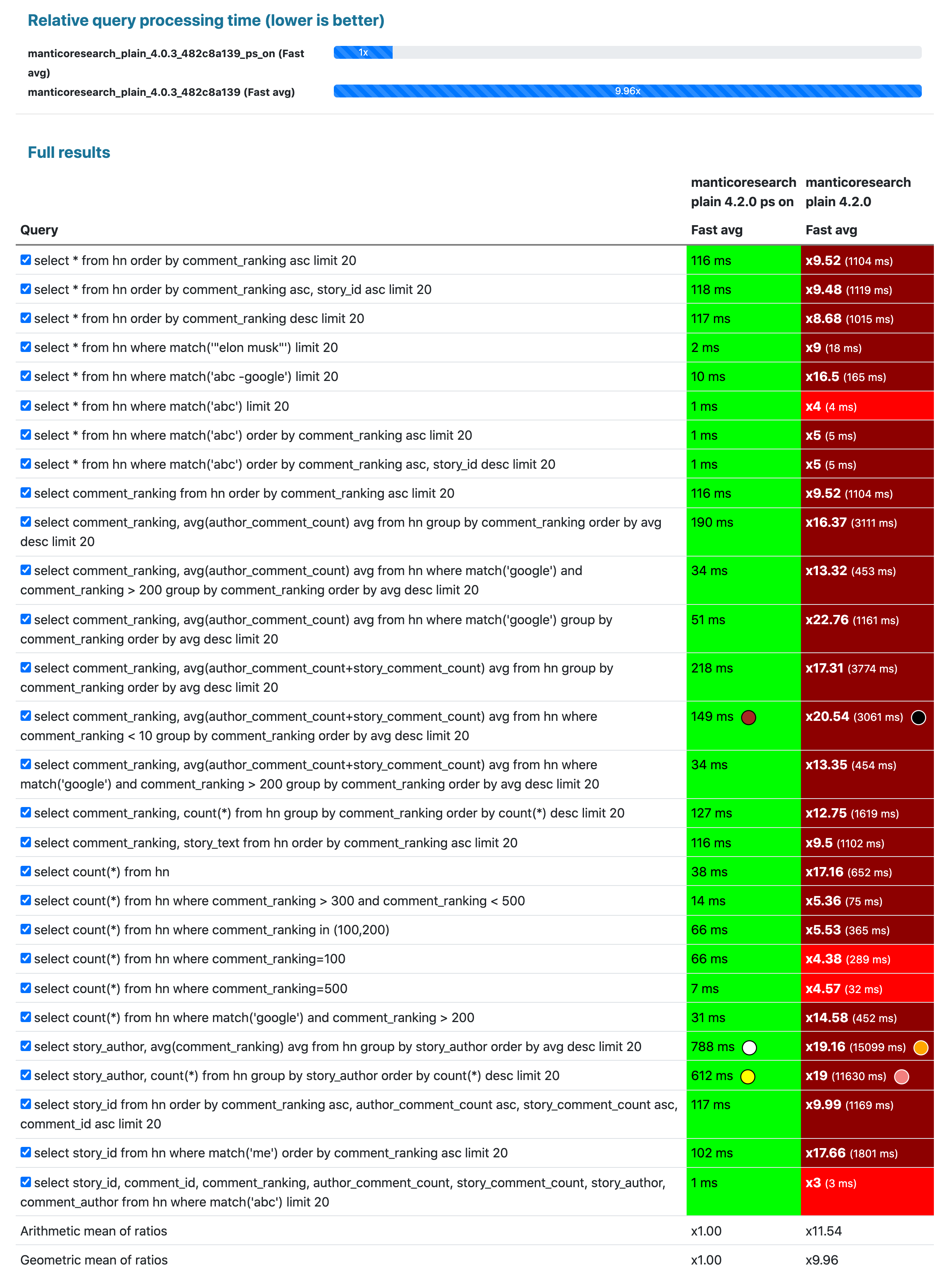
Pseudo-sharding support for real-time indexes and full-text queries. In previous release we added limited pseudo sharding support. Starting from this version you can get all benefits of the pseudo sharding and your multi-core processor by just enabling searchd.pseudo_sharding. The coolest thing is that you don’t need to do anything with your indexes or queries for that, just enable it and if you have free CPU it will be used to lower your response time. It supports plain and real-time indexes for full-text, filtering and analytical queries. For example, here is how enabling pseudo sharding can make most queries’ response time in average about 10x lower on Hacker news curated comments dataset multiplied 100 times (116 million docs in a plain index).
PQ transactions are now atomic and isolated. Previously PQ transactions support was limited. It enables much faster REPLACE into PQ, especially when you need to replace a lot of rules at once. Performance details:
4.0.2
It takes 48 seconds to insert 1M PQ rules and 406 seconds to REPLACE just 40K in 10K batches.
root@perf3 ~ # mysql -P9306 -h0 -e "drop table if exists pq; create table pq (f text, f2 text, j json, s string) type='percolate';"; date; for m in `seq 11000`; do (echo -n "insert into pq (id,query,filters,tags) values "; for n in `seq 11000`; do echo -n "(0,'@f (cat | ( angry dog ) | (cute mouse)) @f2 def', 'j.json.language=\"en\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; [ $n !=1000 ] && echo -n ","; done; echo ";")|mysql -P9306 -h0; done; date; mysql -P9306 -h0 -e "select count(*) from pq"Wed Dec2210:24:30 AM CET 2021Wed Dec2210:25:18 AM CET 2021+----------+| count(*) |+----------+| 1000000 |+----------+root@perf3 ~ # date; (echo "begin;"; for offset in `seq 01000030000`; do n=0; echo "replace into pq (id,query,filters,tags) values "; foridin `mysql -P9306 -h0 -NB -e "select id from pq limit $offset, 10000 option max_matches=1000000"`; do echo "($id,'@f (tiger | ( angry bear ) | (cute panda)) @f2 def', 'j.json.language=\"de\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; n=$((n+1)); [ $n !=10000 ] && echo -n ","; done; echo ";"; done; echo "commit;") >/tmp/replace.sql; dateWed Dec2210:26:23 AM CET 2021Wed Dec2210:26:27 AM CET 2021root@perf3 ~ # time mysql -P9306 -h0 </tmp/replace.sqlreal 6m46.195suser 0m0.035ssys 0m0.008s
4.2.0
It takes 34 seconds to insert 1M PQ rules and 23 seconds to REPLACE them in 10K batches.
root@perf3 ~ # mysql -P9306 -h0 -e "drop table if exists pq; create table pq (f text, f2 text, j json, s string) type='percolate';"; date; for m in `seq 11000`; do (echo -n "insert into pq (id,query,filters,tags) values "; for n in `seq 11000`; do echo -n "(0,'@f (cat | ( angry dog ) | (cute mouse)) @f2 def', 'j.json.language=\"en\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; [ $n !=1000 ] && echo -n ","; done; echo ";")|mysql -P9306 -h0; done; date; mysql -P9306 -h0 -e "select count(*) from pq"Wed Dec2210:06:38 AM CET 2021Wed Dec2210:07:12 AM CET 2021+----------+| count(*) |+----------+| 1000000 |+----------+root@perf3 ~ # date; (echo "begin;"; for offset in `seq 010000990000`; do n=0; echo "replace into pq (id,query,filters,tags) values "; foridin `mysql -P9306 -h0 -NB -e "select id from pq limit $offset, 10000 option max_matches=1000000"`; do echo "($id,'@f (tiger | ( angry bear ) | (cute panda)) @f2 def', 'j.json.language=\"de\"', '{\"tag1\":\"tag1\",\"tag2\":\"tag2\"}')"; n=$((n+1)); [ $n !=10000 ] && echo -n ","; done; echo ";"; done; echo "commit;") >/tmp/replace.sql; dateWed Dec2210:12:31 AM CET 2021Wed Dec2210:14:00 AM CET 2021root@perf3 ~ # time mysql -P9306 -h0 </tmp/replace.sqlreal 0m23.248suser 0m0.891ssys 0m0.047s
Minor changes
optimize_cutoff is now available as a configuration option in section searchd. It’s useful when you want to limit the RT chunks count in all your indexes to a particular number globally.
PR #598 bigint support for YEAR() and other timestamp functions.
Commit 8e85 Adaptive rt_mem_limit. Previously Manticore Search was collecting exactly up to rt_mem_limit of data before saving a new disk chunk to disk, and while saving was still collecting up to 10% more (aka double-buffer) to minimize possible insert suspension. If that limit was also exhausted, adding new documents was blocked until the disk chunk was fully saved to disk. The new adaptive limit is built on the fact that we have auto-optimize now, so it’s not a big deal if disk chunks do not fully respect rt_mem_limit and start flushing a disk chunk earlier. So, now we collect up to 50% of rt_mem_limit and save that as a disk chunk. Upon saving we look at the statistics (how much we’ve saved, how many new documents have arrived while saving) and recalculate the initial rate which will be used next time. For example, if we saved 90 million documents, and another 10 million docs arrived while saving, the rate is 90%, so we know that next time we can collect up to 90% of rt_mem_limit before starting flushing another disk chunk. The rate value is calculated automatically from 33.3% to 95%.
Binlog version was increased, binlog from previous version won’t be replayed, so make sure you stop Manticore Search cleanly during upgrade: no binlog files should be in /var/lib/manticore/binlog/ except binlog.meta after stopping the previous instance.
Commit 3f65 new column “chain” in show threads option format=all. It shows stack of some task info tickets, most useful for profiling needs, so if you are parsing show threads output be aware of the new column.
searchd.workers was obsoleted since 3.5.0, now it’s deprecated, if you still have it in your configuration file it will trigger a warning on start. Manticore Search will start, but with a warning.
If you use PHP and PDO to access Manticore you need to do PDO::ATTR_EMULATE_PREPARES
Bugfixes
❗Issue #650 Manticore 4.0.2 slower than Manticore 3.6.3. 4.0.2 was faster than previous versions in terms of bulk inserts, but significantly slower for single document inserts. It’s been fixed in 4.2.0.
❗Commit 22f4 RT index could get corrupted under intensive REPLACE load, or it could crash
Commit 03be fixed average at merging groupers and group N sorter; fixed merge of aggregates
Issue #679 Batch queries causing crashes again with v4.0.3
Commit f7f8 fixed daemon crash on startup trying to re-join cluster with invalid nodes list
Issue #643 Manticore 4.0.2 does not accept connections after batch of inserts
Issue #635 FACET query with ORDER BY JSON.field or string attribute could crash
Issue #634 Crash SIGSEGV on query with packedfactors
Commit 4165 morphology_skip_fields was not supported by create table
Version 4.0.2, Sep 21 2021
Major new features
Full support of Manticore Columnar Library. Previously Manticore Columnar Library was supported only for plain indexes. Now it’s supported:
in real-time indexes for INSERT, REPLACE, DELETE, OPTIMIZE
in replication
in ALTER
in indextool --check
Automatic indexes compaction (Issue #478). Finally, you don’t have to call OPTIMIZE manually or via a crontask or other kind of automation. Manticore now does it for you automatically and by default. You can set default compaction threshold via optimize_cutoff global variable.
Chunk snapshots and locks system revamp. These changes may be invisible from outside at first glance, but they improve the behaviour of many things happening in real-time indexes significantly. In a nutshell, previously most Manticore data manipulation operations relied on locks heavily, now we use disk chunk snapshots instead.
Significantly faster bulk INSERT performance into a real-time index. For example on Hetzner’s server AX101 with SSD, 128 GB of RAM and AMD’s Ryzen™ 9 5950X (16*2 cores) with 3.6.0 you could get 236K docs per second inserted into a table with schema name text, email string, description text, age int, active bit(1) (default rt_mem_limit, batch size 25000, 16 concurrent insert workers, 16 million docs inserted overall). In 4.0.2 the same concurrency/batch/count gives 357K docs per second.
read operations (e.g. SELECTs, replication) are performed with snapshots
operations that just change internal index structure without modifying schema/documents (e.g. merging RAM segments, saving disk chunks, merging disk chunks) are performed with read-only snapshots and replace the existing chunks in the end
UPDATEs and DELETEs are performed against existing chunks, but for the case of merging that may be happening the writes are collected and are then applied against the new chunks
UPDATEs acquire an exclusive lock sequentially for every chunk. Merges acquire a shared lock when entering the stage of collecting attributes from the chunk. So at the same time only one (merge or update) operation has access to attributes of the chunk.
when merging gets to the phase, when it needs attributes it sets a special flag. When UPDATE finishes, it checks the flag, and if it’s set, the whole update is stored in a special collection. Finally, when the merge finishes, it applies the updates set to the newborn disk chunk.
ALTER runs via an exclusive lock
replication runs as a usual read operation, but in addition saves the attributes before SST and forbids updates during the SST
ALTER can add/remove a full-text field (in RT mode). Previously it could only add/remove an attribute.
🔬 Experimental: pseudo-sharding for full-scan queries - allows to parallelize any non-full-text search query. Instead of preparing shards manually you can now just enable new option searchd.pseudo_sharding and expect up to CPU cores lower response time for non-full-text search queries. Note it can easily occupy all existing CPU cores, so if you care not only about latency, but throughput too - use it with caution.
Minor changes
Linux Mint and Ubuntu Hirsute Hippo are supported via APT repository
faster update by id via HTTP in big indexes in some cases (depends on the ids distribution)
time curl -X POST -d '{"update":{"index":"idx","id":4611686018427387905,"doc":{"mode":0}}}' -H "Content-Type: application/x-ndjson" http://127.0.0.1:6358/json/bulk
real 0m43.783s
user 0m0.008s
sys 0m0.007s
4.0.2
time curl -X POST -d '{"update":{"index":"idx","id":4611686018427387905,"doc":{"mode":0}}}' -H "Content-Type: application/x-ndjson" http://127.0.0.1:6358/json/bulk
real 0m0.006s
user 0m0.004s
sys 0m0.001s
custom startup flags for systemd. Now you don’t need to start searchd manually in case you need to run Manticore with some specific startup flag
new function LEVENSHTEIN() which calculates Levenshtein distance
added new searchd startup flags--replay-flags=ignore-trx-errors and --replay-flags=ignore-all-errors so one can still start searchd if the binlog is corrupted
the new version can read older indexes, but the older versions can’t read Manticore 4’s indexes
removed implicit sorting by id. Sort explicitly if required
charset_table’s default value changes from 0..9, A..Z->a..z, _, a..z, U+410..U+42F->U+430..U+44F, U+430..U+44F, U+401->U+451, U+451 to non_cjk
OPTIMIZE happens automatically. If you don’t need it make sure to set auto_optimize=0 in section searchd in the configuration file
Issue #616ondisk_attrs_default were deprecated, now they are removed
for contributors: we now use Clang compiler for Linux builds as according to our tests it can build a faster Manticore Search and Manticore Columnar Library
if max_matches is not specified in a search query it gets updated implicitly with the lowest needed value for the sake of performance of the new columnar storage. It can affect metric total in SHOW META, but not total_found which is the actual number of found documents.
Migration from Manticore 3
make sure you a stop Manticore 3 cleanly:
no binlog files should be in /var/lib/manticore/binlog/ (only binlog.meta should be in the directory)
otherwise the indexes Manticore 4 can’t reply binlogs for won’t be run
the new version can read older indexes, but the older versions can’t read Manticore 4’s indexes, so make sure you make a backup if you want to be able to rollback the new version easily
if you run a replication cluster make sure you:
stop all your nodes first cleanly
and then start the node which was stopped last with --new-cluster (run tool manticore_new_cluster in Linux).
Commit 696f - fixed crash during SST on joiner with active index; added sha1 verify at joiner node at writing file chunks to speed up index loading; added rotation of changed index files at joiner node on index load; added removal of index files at joiner node when active index gets replaced by a new index from donor node; added replication log points at donor node for sending files and chunks
Commit b296 - crash on JOIN CLUSTER in case the address is incorrect
Commit 418b - while initial replication of a large index the joining node could fail with ERROR 1064 (42000): invalid GTID, (null), the donor could become unresponsive while another node was joining
Commit 6fd3 - hash could be calculated wrong for a big index which could result in replication failure
Issue #615 - replication failed on cluster restart
Issue #618 - searchd –stopwait fails under root. It also fixes systemctl behaviour (previously it was showing failure for ExecStop and didn’t wait long enough for searchd to stop properly)
Issue #619 - INSERT/REPLACE/DELETE vs SHOW STATUS. command_insert, command_replace and others were showing wrong metrics
Issue #620 - charset_table for a plain index had a wrong default value
Issue #607 - Manticore cluster node crashes when unable to resolve a node by name
Issue #623 - replication of updated index can lead to undefined state
Commit ca03 - indexer could hang on indexing a plain index source with a json attribute
Commit 53c7 - fixed not equal expression filter at PQ index
Commit ccf9 - fixed select windows at list queries above 1000 matches. SELECT * FROM pq ORDER BY id desc LIMIT 1000 , 100 OPTION max_matches=1100 was not working previously
Commit a048 - HTTPS request to Manticore could cause warning like “max packet size(8388608) exceeded”
Issue #648 - Manticore 3 could hang after a few updates of string attributes
Fully revised histograms. When building an index Manticore also builds histograms for each field in it, which it then uses for faster filtering. In 3.6.0 the algorithm was fully revised and you can get a higher performance if you have a lot of data and do a lot of filtering.
Minor changes
tool manticore_new_cluster [--force] useful for restarting a replication cluster via systemd
faster JSON parsing, our tests show 3-4% lower latency on queries like WHERE json.a = 1
non-documented command DEBUG SPLIT as a prerequisite for automatic sharding/rebalancing
Bugfixes
Issue #584 - inaccurate and unstable FACET results
Issue #506 - Strange behavior when using MATCH: those who suffer from this issue need to rebuild the index as the problem was on the phase of building an index
Issue #387 - intermittent core dump when running query with SNIPPET() function
Stack optimizations useful for processing complex queries:
Commit 4795 - percolate index filter and tags were empty for empty stored query (test 369)
Commit c3f0 - breaks of replication SST flow at network with long latency and high error rate (different data centers replication); updated replication command version to 1.03
Commit ba2d - joiner lock cluster on write operations after join into cluster (test 385)
Commit de4d - wildcards matching with exact modifier (test 321)
Commit 812d - wrong weight for phrase starting with wildcard
Commit 1771 - percolate query with wildcards generate terms without payload on matching causes interleaved hits and breaks matching (test 417)
Commit aa0d - fixed calculation of ‘total’ in case of parallelized query
Commit 18d8 - crash in Windows with multiple concurrent sessions at daemon
Commit 8443 - some index settings could not be replicated
Commit 9341 - On high rate of adding new events netloop sometimes freeze because of atomic ‘kick’ event being processed once for several events a time and loosing actual actions from them status of the query, not the server status
Commit d805 - New flushed disk chunk might be lost on commit
Commit ff71 - TRUNCATE WITH RECONFIGURE worked wrong with stored fields
Breaking changes:
New binlog format: you need to make a clean stop of Manticore before upgrading
Index format slightly changes: the new version can read you existing indexes fine, but if you decide to downgrade from 3.6.0 to an older version the newer indexes will be unreadable
Replication format change: don’t replicate from an older version to 3.6.0 and vice versa, switch to the new version on all your nodes at once
reverse_scan is deprecated. Make sure you don’t use this option in your queries since 3.6.0 since they will fail otherwise
As of this release we don’t provide builds for RHEL6, Debian Jessie and Ubuntu Trusty any more. If it’s mission critical for you to have them supported contact us
Deprecations
No more implicit sorting by id. If you rely on it make sure to update your queries accordingly
Search option reverse_scan has been deprecated
Version 3.5.4, Dec 10 2020
New Features
New Python, Javascript and Java clients are generally available now and are well documented in this manual.
automatic drop of a disk chunk of a real-time index. This optimization enables dropping a disk chunk automatically when OPTIMIZing a real-time index when the chunk is obviously not needed any more (all the documents are suppressed). Previously it still required merging, now the chunk can be just dropped instantly. The cutoff option is ignored, i.e. even if nothing is actually merged an obsoleted disk chunk gets removed. This is useful in case you maintain retention in your index and delete older documents. Now compacting such indexes will be faster.
Issue #453 New option indexer.ignore_non_plain=1 is useful in case you run indexer --all and have not only plain indexes in the configuration file. Without ignore_non_plain=1 you’ll get a warning and a respective exit code.
Commit ea68 count distinct returns 0 at low max_matches on a local index
Commit 362f When using aggregation stored texts are not returned in hits
Version 3.5.2, Oct 1 2020
New features
OPTIMIZE reduces disk chunks to a number of chunks ( default is 2* No. of cores) instead of a single one. The optimal number of chunks can be controlled by cutoff option.
NOT operator can be now used standalone. By default it is disabled since accidental single NOT queries can be slow. It can be enabled by setting new searchd directive not_terms_only_allowed to 0.
New setting max_threads_per_query sets how many threads a query can use. If the directive is not set, a query can use threads up to the value of threads. Per SELECT query the number of threads can be limited with OPTION threads=N overriding the global max_threads_per_query.
Percolate indexes can be now be imported with IMPORT TABLE.
HTTP API /search receives basic support for faceting/grouping by new query node aggs.
Minor changes
If no replication listen directive is declared, the engine will try to use ports after the defined ‘sphinx’ port, up to 200.
listen=...:sphinx needs to be explicit set for SphinxSE connections or SphinxAPI clients.
SHOW INDEX STATUS outputs new metrics: killed_documents, killed_rate, disk_mapped_doclists, disk_mapped_cached_doclists, disk_mapped_hitlists and disk_mapped_cached_hitlists.
SQL command status now outputs Queue\Threads and Tasks\Threads.
Deprecations:
dist_threads is completely deprecated now, searchd will log a warning if the directive is still used.
Docker
The official Docker image is now based on Ubuntu 20.04 LTS
Packaging
Besides the usual manticore package, you can also install Manticore Search by components:
manticore-server-core - provides searchd, manpage, log dir, API and galera module. It will also install manticore-common as the dependency.
manticore-server - provides automation scripts for core (init.d, systemd), and manticore_new_cluster wrapper. It will also install manticore-server-core as the dependency.
manticore-tools - provides auxiliary tools ( indexer, indextool etc.), their manpages and examples. It will also install manticore-common as the dependency.
manticore-icudata (RPM) or manticore-icudata-65l (DEB) - provides ICU data file for icu morphology usage.
manticore-devel (RPM) or manticore-dev (DEB) - provides dev headers for UDFs.
Bugifixes
Commit 2a47 Crash of daemon at grouper at RT index with different chunks
Commit f0b3 Token filter plugin vs zero position deltas
Commit a49e Change ‘FAIL’ to ‘WARNING’ on multiple hits
Version 3.5.0, 22 Jul 2020
Major new features:
This release took so long, because we were working hard on changing multitasking mode from threads to coroutines. It makes configuration simpler and queries parallelization much more straightforward: Manticore just uses given number of threads (see new setting threads) and the new mode makes sure it’s done in the most optimal way.
any highlighting that works with several fields (highlight({},'field1, field2') or highlight in json queries) now applies limits per-field by default.
any highlighting that works with plain text (highlight({}, string_attr) or snippet() now applies limits to the whole document.
per-field limits can be switched to global limits by limits_per_field=0 option (1 by default).
allow_empty is now 0 by default for highlighting via HTTP JSON.
The same port can now be used for http, https and binary API (to accept connections from a remote Manticore instance). listen = *:mysql is still required for connections via mysql protocol. Manticore now detects automatically the type of client trying to connect to it except for MySQL (due to restrictions of the protocol).
In plain mode it’s called sql_field_string. Now it’s available in RT mode for real-time indexes too. You can use it as shown in the example:
createtable t(f string attributeindexed);insertinto t values(0,'abc','abc');select*from t where match('abc');+---------------------+------+| id | f |+---------------------+------+| 2810845392541843463 | abc |+---------------------+------+1rowinset (0.01 sec)mysql>select*from t where f='abc';+---------------------+------+| id | f |+---------------------+------+| 2810845392541843463 | abc |+---------------------+------+1rowinset (0.00 sec)
thread_stack now limits maximum thread stack, not initial.
Improved SHOW THREADS output.
Display progress of long CALL PQ in SHOW THREADS.
cpustat, iostat, coredump can be changed during runtime with SET.
SET [GLOBAL] wait_timeout=NUM implemented ,
Breaking changes:
Index format has been changed. Indexes built in 3.5.0 cannot be loaded by Manticore version < 3.5.0, but Manticore 3.5.0 understands older formats.
INSERT INTO PQ VALUES() (i.e. without providing column list) previously expected exactly (query, tags) as the values. It’s been changed to (id,query,tags,filters). The id can be set to 0 if you want it to be auto-generated.
allow_empty=0 is a new default in highlighting via HTTP JSON interface.
Only absolute paths are allowed for external files (stopwords, exceptions etc.) in CREATE TABLE/ALTER TABLE.
Deprecations:
ram_chunks_count was renamed to ram_chunk_segments_count in SHOW INDEX STATUS.
workers is obsolete. There’s only one workers mode now.
dist_threads is obsolete. All queries are as much parallel as possible now (limited by threads and jobs_queue_size).
max_children is obsolete. Use threads to set the number of threads Manticore will use (set to the # of CPU cores by default).
queue_max_length is obsolete. Instead of that in case it’s really needed use jobs_queue_size to fine-tune internal jobs queue size (unlimited by default).
All /json/* endpoints are now available w/o /json/, e.g. /search, /insert, /delete, /pq etc.
field meaning “full-text field” was renamed to “text” in describe. 3.4.2:
mysql> describe t;+-------+--------+----------------+| Field | Type | Properties |+-------+--------+----------------+| id | bigint | || f | field | indexed stored |+-------+--------+----------------+
3.5.0:
mysql> describe t;+-------+--------+----------------+| Field | Type | Properties |+-------+--------+----------------+| id | bigint | || f | text | indexed stored |+-------+--------+----------------+
Cyrillic и doesn’t map to i in non_cjk charset_table (which is a default) as it affected Russian stemmers and lemmatizers too much.
read_timeout. Use network_timeout instead which controls both reading and writing.
Packages
Ubuntu Focal 20.04 official package
deb package name changed from manticore-bin to manticore
agent_retry_count in case of agents with mirrors gives the value of retries per mirror instead of per agent, the total retries per agent being agent_retry_count*mirrors.
Commit 3359 refactored master-agent network polling on kqueue-based systems (Mac OS X, BSD).
Version 2.6.0, 29 December 2017
Features and improvements
HTTP JSON: JSON queries can now do equality on attributes, MVA and JSON attributes can be used in inserts and updates, updates and deletes via JSON API can be performed on distributed indexes
Removed support for 32-bit docids from the code. Also removed all the code that converts/loads legacy indexes with 32-bit docids.
Morphology only for certain fields . A new index directive morphology_skip_fields allows defining a list of fields for which morphology does not apply.
lots of minor fixes after thorough static code analysis
other minor bugfixes
Upgrade
In this release we’ve changed internal protocol used by masters and agents to speak with each other. In case you run Manticoresearch in a distributed environment with multiple instances make sure your first upgrade agents, then the masters.
Version 2.5.1, 23 November 2017
Features and improvements
JSON queries on HTTP API protocol. Supported search, insert, update, delete, replace operations. Data manipulation commands can be also bulked, also there are some limitations currently as MVA and JSON attributes can’t be used for inserts, replaces or updates.